Llama 2
Meta hat Llama 2 (Large Language Model Meta AI) freigegeben, eine Sammlung von großen Sprachmodellen (LLMs), die mit wenigen Einschränkungen frei verwendet werden können. Die Modelle können auf jedem Gerät mit ausreichender Rechenleistung geladen und ausgeführt werden, bieten aber auch die Grundlage für die Erweiterung und Modifikation eigener Modelle. Dieser Ansatz steht im Kontrast zu Unternehmen wie OpenAI oder Google, deren Modelle (GPT-4 bzw. PaLM 2) nur über bereitgestellte Software (ChatGPT bzw. Bard) oder Schnittstellen genutzt werden können, die stets in der Cloud laufen. Die erste Version von LLaMA sorgte bereits im Februar für Aufsehen in der Fachcommunity, da sie ursprünglich für die Forschung gedacht war, aber durch einen Leak im Internet öffentlich zugänglich wurde und daraufhin als Basis für zahlreiche Modelle und Experimente diente.
Die Veröffentlichungspolitik von Meta ist nicht unumstritten. Kritiker befürchten einen möglichen Missbrauch von offenen Sprachmodellen, etwa durch die vergleichsweise einfach Erstellung von Desinformationen, Hassreden oder anderen schädlichen Inhalten. Meta hingegen vertritt die Ansicht, dass ein offener Ansatz erforderlich ist, um zu verhindern, dass die Kontrolle über KI auf wenige mächtige Unternehmen beschränkt bleibt.
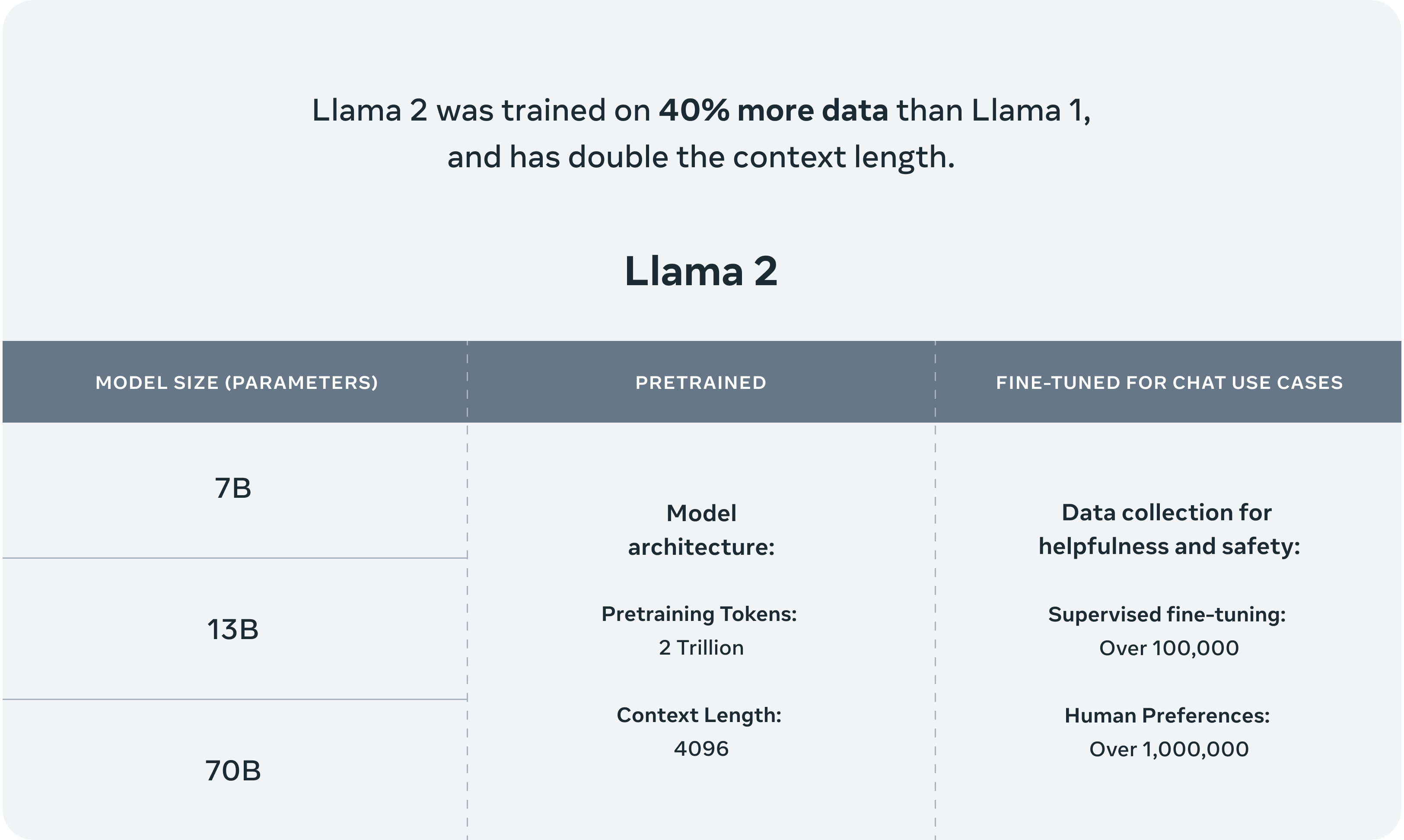
Meta hat Llama 2 in sechs verschiedenen Ausführungen veröffentlicht. Das Grundmodell ist ein Update von LLaMA 1 und kommt in Varianten mit 7B, 13B und 70B Parametern, sowie in einer für Dialoge bzw. Chats optimierten Version (Llama 2-Chat), ebenfalls mit 7B, 13B und 70B Parametern.
Jedoch gibt Meta nicht alle Informationen über die Sprachmodelle preis. Etwa hat der Konzern keine Informationen über den Datensatz veröffentlicht, der für das Training von Llama 2 verwendet wurde.
In der Model Card heißt es lediglich:
„Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.“ (S. 76)
Während es zum Stand der Daten heißt:
„The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.“ (S. 76)
Ebenfalls schreibt Meta im Paper:
„We made an effort to remove data from certain sites known to contain a high volume of personal information about private individuals. We trained on 2 trillion tokens of data as this provides a good performance-cost trade-off, up-sampling the most factual sources in an effort to increase knowledge and dampen hallucinations.“ (S. 5)
Die einzelnen Modelle und Informationen über Llama 2 können über die folgenden Links gefunden werden: Blog, GitHub, Hugging Face, Paper
Dieser Beitrag wurde am 03.08.2023 aktualisiert, um die Nutzungsmöglichkeiten zu präzisieren.